Серьезность и приоритет багов — в чем разница? — testengineer.ru
Дата
Категория
#промо
💰 Какой была ваша первая зарплата в QA и как вы искали первую работу? Мега-обсуждение в нашем телеграм-канале.
Читать в телеграм
- Серьезность
- Приоритет
- Глобальный приоритет
- Высокий приоритет и низкая серьезность
- Высокая серьезность и низкий приоритет
Для отслеживания багов в программах используются различные инструменты. В крупных компаниях эти инструменты объединяются в общую систему, которой пользуется много сотрудников. И все эти люди должны как-то ориентироваться в срочности работы над багами.
Поэтому баги, внесенные в системы отслеживания (bug-tracking системы), дифференцируются.
Каждый баг имеет атрибуты серьезности (Severity) и приоритета (Priority). На первый взгляд может показаться, что разницы между этими понятиями нет, но она все же есть. Серьезность больше касается технической стороны дела, а приоритет — организационной.
На первый взгляд может показаться, что разницы между этими понятиями нет, но она все же есть. Серьезность больше касается технической стороны дела, а приоритет — организационной.
Severity — это атрибут, характеризующий влияние бага на общую функциональность тестируемого продукта.
Степень серьезности бага больше касается функциональности, поэтому она присваивается тестировщиком. Именно он чаще всего оценивает, насколько конкретная функция может влиять на общую работу тестируемого продукта.
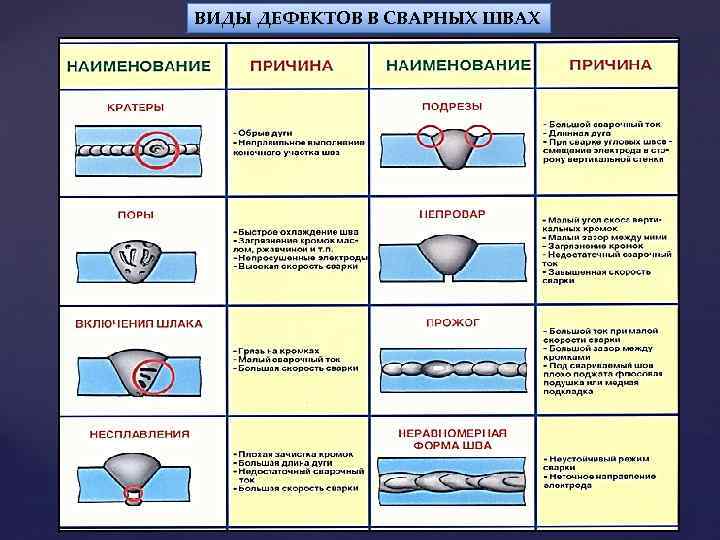
Пример классификации серьезности багов:
- Blocker. Блокирующая ошибка. Она делает невозможной всю последующую работу с программой. Для возобновления работы нужно исправить Blocker.
- Critical.
- Major. Существенный баг.
 Затрудняет работу основного функционала или делает невозможным использование дополнительных функций.
Затрудняет работу основного функционала или делает невозможным использование дополнительных функций. - Minor. Незначительный баг. На функционал системы влияет относительно мало, затрудняет использование дополнительных функций. Для обхода этого бага могут быть очевидные пути.
- Trivial. Тривиальный баг. Не влияет на функционал проекта, но ухудшает общее впечатление от работы с продуктом.
Приоритет — атрибут, определяющий скорость устранения бага.
Приоритет бага сперва определяет инициатор, но в дальнейшем он корректируется менеджером продукта. Именно менеджер имеет общее представление о тестируемой системе и понимает, насколько срочно нужно исправить тот или иной баг.
Виды приоритетов:
- Top. Наивысший приоритет. Назначается экстренным ситуациям, которые очень отрицательно влияют на продукт или даже бизнес компании. Такие баги нужно устранять немедленно.
- High. Высокий приоритет. Назначается багам, которые должны быть устранены в первую очередь.
- Normal. Обычный приоритет, назначается по умолчанию. Эти баги устраняются во вторую очередь, в штатном порядке.
- Low. Низкий приоритет. Назначается багам, не влияющим на функционал. Исправление таких багов происходит в последнюю очередь, если есть время и ресурсы.
Также нужно упомянуть о частоте проявления бага.
Частота (Frequency) — это показатель количества пользователей, которые сталкиваются с ошибкой. Определяется при анализе алгоритмов.
Частота бывает:
- High. Высокая: с багом сталкиваются больше 80% пользователей.
- Medium. Средняя: баг обнаружат от 30% до 80% пользователей.
- Low. Низкая: баг проявляется у 10-30% пользователей.
- Very low. Незначительная: такой баг встретится меньше чем 10% пользователей.

Для определения глобального приоритета необходимо определить частоту проявления бага. Частота влияет на приоритет, а приоритет и серьезность влияют на глобальный приоритет бага.
Таким образом, для определения глобального приоритета бага нужно:
- Определить серьезность бага.
- Определить частоту (независимо от серьезности и приоритета).
- Рассчитать влияние частоты на изначально определенный приоритет.
Если частота у бага высокая, приоритет возрастает на одну позицию. Скажем, если изначально приоритет был Normal, но частота высокая, приоритет определяется как High.
Средняя частота бага меняет приоритет только с низкого на обычный.
Низкая или незначительная частота вообще не меняет приоритет бага.
Для определения глобального приоритета можно пользоваться следующей таблицей:
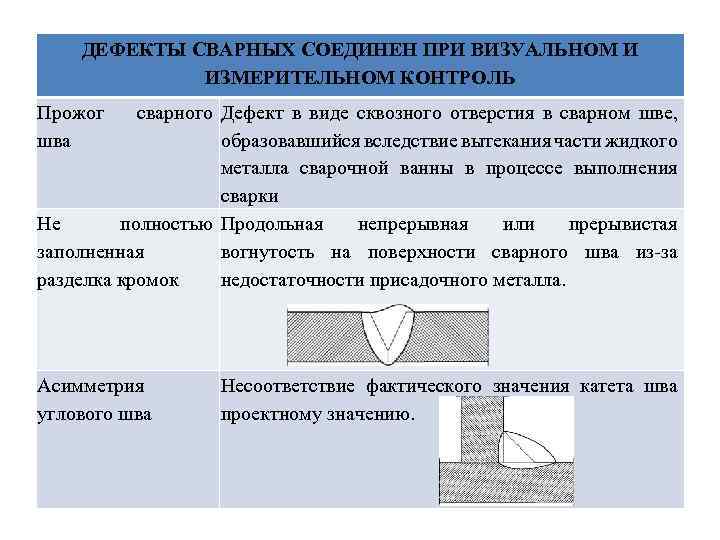
| Приоритет/Серьезность | Blocker | Critical | Minor | Trivial |
|---|---|---|---|---|
| Critical | Critical | Minor | Trivial | |
| Medium | Critical | Critical | Minor | Trivial |
| Low | — | — | Trivial | Trivial |
Если глобальный приоритет — Critical, значит, баг нужно непременно исправить. Баги с приоритетом Minor тоже желательно исправить до релиза, хотя некоторое количество таких дефектов может остаться в проекте. Баги с приоритетом Trivial могут вообще не исправляться.
Баги с приоритетом Minor тоже желательно исправить до релиза, хотя некоторое количество таких дефектов может остаться в проекте. Баги с приоритетом Trivial могут вообще не исправляться.
Вот пара примеров:
- Кнопки перекрывают друг друга. Они кликабельны, но визуальное впечатление портится.
- Логотип компании на главной странице содержит орфографическую ошибку. На функционал это вообще не влияет, но портит пользовательский опыт. Этот баг нужно исправить с высоким приоритетом, несмотря не то, что на продукт он влияет минимально.
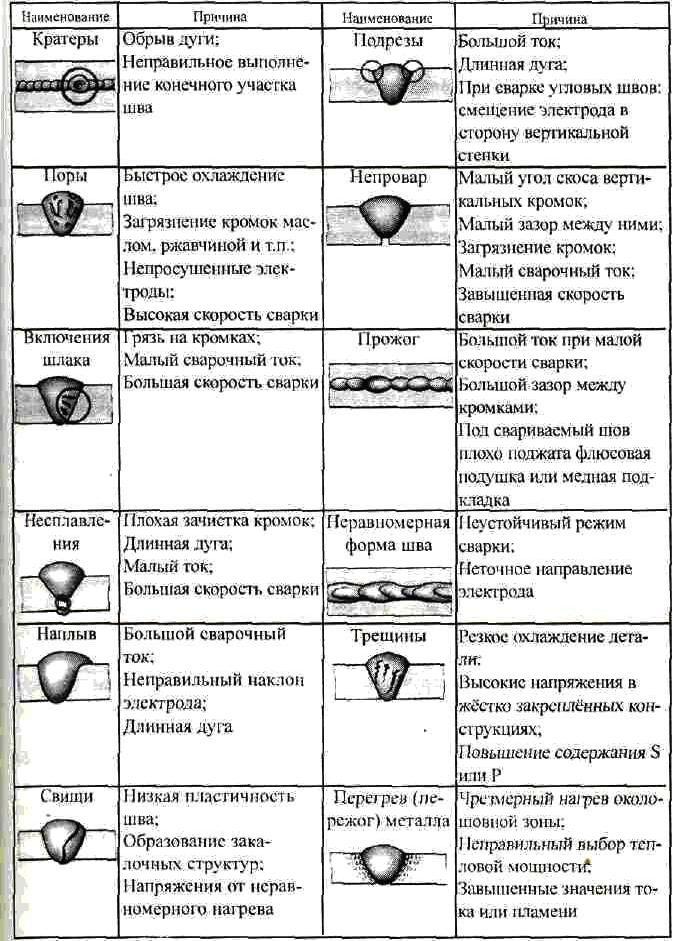
Такое сочетание бывает у багов, которые возникают в отдельных функциях программы. Эти баги не позволяют пользоваться системой, при этом обойти их невозможно.
Примеры:
- Домашняя страница сайта ужасно выглядит в старых браузерах. Перекрывается текст, не загружается логотип. Это мешает пользоваться продуктом, поэтому серьезность бага высокая. Но так как очень мало пользователей открывают сайт при помощи устаревшего браузера, такой баг получает низкий приоритет.
- Допустим, у нас есть приложение для банкинга. Оно правильно рассчитывает ежедневный, ежемесячный и ежеквартальный отчет, но при расчете годового возникают проблемы. Этот баг имеет высокую степень серьезности. Но если сейчас формирование годовой отчетности не актуально, такой дефект имеет низкий приоритет: его можно исправить в следующем релизе.
Итоги
Приоритет и серьезность багов — ключевые атрибуты, в соответствии с которыми определяется очередность исправления. Если неверно присвоить багу приоритет и серьезность, эффективность исправления ошибки сильно снизится. Это может нанести вред бизнесу и привести к финансовым потерям. Поэтому очень важно, чтобы и тестировщики, и разработчики понимали суть этих терминов и пользовались ими правильно.
Это может нанести вред бизнесу и привести к финансовым потерям. Поэтому очень важно, чтобы и тестировщики, и разработчики понимали суть этих терминов и пользовались ими правильно.
Читать в телеграм
Последние публикации
Про Тестинг — Тестирование — Баг репорт
► в закладки
Раздел: Тестирование > Тестовые Артефакты > Баг Репорт > Серьезность и Приоритет Дефекта
Разные системы баг трекинга предлагают нам разные пути описания серьезности и приоритета баг репорта, неизменным остается лишь смысл, вкладываемый в эти поля.
Все знают такой баг-трекер, как Atlassian JIRA. В нем, начиная с какой-то версии вместо одновременного использования полей Severity и Priority, оставили только Priority, которое собрало в себе свойства обоих полей: Originally, JIRA did have both a Priority and a Severity field. The Severity field was removed for a number of reasons… Таким образом, те кто привык работать с JIRA не всегда понимают разницу между этими понятиями, так как не имели опыта их совместного использования.
Серьезность (Severity) — это атрибут, характеризующий влияние дефекта на работоспособность приложения.
Градация Серьезности дефекта (Severity)
S1 Блокирующая (Blocker)
Блокирующая ошибка, приводящая приложение в нерабочее состояние, в результате которого дальнейшая работа с тестируемой системой или ее ключевыми функциями становится невозможна. Решение проблемы необходимо для дальнейшего функционирования системы.
S2 Критическая (Critical)
Критическая ошибка, неправильно работающая ключевая бизнес логика, дыра в системе безопасности, проблема, приведшая к временному падению сервера или приводящая в нерабочее состояние некоторую часть системы, без возможности решения проблемы, используя другие входные точки.
S3 Значительная (Major)
Значительная ошибка, часть основной бизнес логики работает некорректно. Ошибка не критична или есть возможность для работы с тестируемой функцией, используя другие входные точки.
S4 Незначительная (Minor)
Незначительная ошибка, не нарушающая бизнес логику тестируемой части приложения, очевидная проблема пользовательского интерфейса.
S5 Тривиальная (Trivial)
Тривиальная ошибка, не касающаяся бизнес логики приложения, плохо воспроизводимая проблема, малозаметная посредствам пользовательского интерфейса, проблема сторонних библиотек или сервисов, проблема, не оказывающая никакого влияния на общее качество продукта.
Градация Приоритета дефекта (Priority)
P1 Высокий (High)
Ошибка должна быть исправлена как можно быстрее, т. к. ее наличие является критической для проекта.
к. ее наличие является критической для проекта.
P2 Средний (Medium)
Ошибка должна быть исправлена, ее наличие не является критичной, но требует обязательного решения.
P3 Низкий (Low)
Ошибка должна быть исправлена, ее наличие не является критичной, и не требует срочного решения.
Порядок исправления ошибок по их приоритетам:
High -> Medium -> Low
Требования к количеству открытых багов
Хотим предложить вам следующий подход к определению требований к количеству открытых багов:
- Наличие открытых дефектов P1, P2 и S1, S2, считается неприемлемым для проекта. Все подобные ситуации требуют срочного решения и идут под контроль к менеджерам проекта.
- Наличие строго ограниченного количества открытых ошибок P3 и S3, S4, S5 не является критичным для проекта и допускается в выдаваемом приложении.
 Количество же открытых ошибок зависит от размера проекта и установленных критериев качества.
Количество же открытых ошибок зависит от размера проекта и установленных критериев качества.
Все требования к открытым ошибкам оговариваются и документируются на этапе принятия решения о качестве разрабатываемого продукта. Как пример документирования подобных требований — это пункт Критерии окончания тестирования в плане тестирования.
Наверх
Качество программного обеспечения на максимальной скорости
Перейти к содержимомуКачество программного обеспечения на максимальной скоростиНатали Найгрен2019-09-27T17:14:27+00:00
Разработка программного обеспечения
Выпуск: Август 1996 г. различные пути. Первый вид качества, о котором люди обычно думают, говоря о «качестве программного обеспечения», — это низкий уровень брака.
Некоторые менеджеры проектов пытаются сократить свои графики, сокращая время, затрачиваемое на методы обеспечения качества, такие как проектирование и проверка кода. Некоторые недооценивают предшествующие действия по анализу требований и проектированию. Другие, опаздывая, пытаются наверстать упущенное, сокращая график тестирования, который уязвим для сокращения, поскольку это элемент критического пути в конце графика.
Некоторые недооценивают предшествующие действия по анализу требований и проектированию. Другие, опаздывая, пытаются наверстать упущенное, сокращая график тестирования, который уязвим для сокращения, поскольку это элемент критического пути в конце графика.
Это одни из худших решений, которые может принять человек, стремящийся к максимальной скорости разработки. В программном обеспечении более высокое качество (в виде меньшего количества дефектов) и сокращение времени разработки идут рука об руку. Рисунок 1 иллюстрирует взаимосвязь между количеством дефектов и временем разработки.
Рисунок 1. Зависимость между количеством дефектов и временем разработки. Как правило, проекты с наименьшим процентом брака также имеют самые короткие сроки.
гифка
Некоторым организациям удалось добиться чрезвычайно низкого уровня дефектов (показан в правой части кривой), и когда вы достигнете этой точки, дальнейшее сокращение количества дефектов приведет к увеличению времени разработки. Это относится к жизненно важным системам, таким как системы жизнеобеспечения на космических кораблях. Это не относится к остальным из нас.
Это относится к жизненно важным системам, таким как системы жизнеобеспечения на космических кораблях. Это не относится к остальным из нас.
Остальным из нас не мешало бы извлечь уроки из открытия, сделанного IBM в 1970-е годы: продукты с наименьшим количеством дефектов также имеют самые короткие сроки (Джонс, 1991). В настоящее время многие организации разрабатывают программное обеспечение с такими уровнями дефектов, которые требуют больше времени, чем необходимо. Изучив около 4000 программных проектов, Кейперс Джонс сообщил, что низкое качество было одной из наиболее распространенных причин превышения графика (1994). Он также сообщил, что низкое качество связано почти с половиной всех отмененных проектов. Опрос, проведенный Институтом разработки программного обеспечения, показал, что более 60 % организаций страдали от неадекватного обеспечения качества (Kitson and Masters 19).93). На кривой на рис. 1 эти организации находятся слева от линии 95-процентного выбытия.
Эта 95-процентная линия удаления — или некоторая точка рядом с ней — важна, потому что этот уровень устранения дефектов перед выпуском, по-видимому, является точкой, в которой проекты достигают кратчайших сроков, минимальных усилий и наивысшего уровня удовлетворенности пользователей. (Джонс, 1991). Если вы обнаружите более 5 процентов своих дефектов после того, как ваш продукт был выпущен, вы уязвимы для проблем, связанных с низким качеством, и вам, вероятно, потребуется больше времени для разработки вашего программного обеспечения, чем вам нужно.
(Джонс, 1991). Если вы обнаружите более 5 процентов своих дефектов после того, как ваш продукт был выпущен, вы уязвимы для проблем, связанных с низким качеством, и вам, вероятно, потребуется больше времени для разработки вашего программного обеспечения, чем вам нужно.
Ярлыки дизайна
Проекты, которые выполняются в спешке, особенно уязвимы для недооценки обеспечения качества на уровне отдельного разработчика. Любой разработчик, которого подтолкнули к быстрому выпуску продукта, знает, насколько сильно может быть давление, чтобы срезать углы, потому что «у нас всего три недели до поставки». Например, вместо того, чтобы писать отдельный, полностью чистый модуль печати, вы можете использовать печать на модуле экрана-дисплея. Вы знаете, что это плохой дизайн, что его нельзя расширять или обслуживать, но у вас нет времени, чтобы сделать это правильно. На вас оказывают давление, чтобы продукт был готов, поэтому вы чувствуете себя обязанным пойти по короткому пути.
Два месяца спустя продукт все еще не отправлен, а срезанные углы возвращаются, чтобы преследовать вас. Вы обнаружите, что пользователи недовольны печатью, и единственный способ удовлетворить их запросы — значительно расширить функциональность печати. К сожалению, за два месяца, прошедших с тех пор, как вы подключили печать к модулю экранного дисплея, функции печати и функции экранного дисплея стали полностью переплетены. Перепроектирование печати и отделение ее от экрана теперь является сложной, трудоемкой и подверженной ошибкам операцией.
Вы обнаружите, что пользователи недовольны печатью, и единственный способ удовлетворить их запросы — значительно расширить функциональность печати. К сожалению, за два месяца, прошедших с тех пор, как вы подключили печать к модулю экранного дисплея, функции печати и функции экранного дисплея стали полностью переплетены. Перепроектирование печати и отделение ее от экрана теперь является сложной, трудоемкой и подверженной ошибкам операцией.
В результате ярлык, который должен был экономить время, на самом деле тратил время впустую следующим образом:
- Первоначальное время, потраченное на разработку и внедрение хака для печати, было полностью потрачено впустую, потому что большая часть этого кода будет выброшена. Время, затраченное на модульное тестирование и отладку кода хака для печати, также было потрачено впустую.
- Необходимо дополнительное время, чтобы удалить код, относящийся к печати, из модуля дисплея.
- Необходимо потратить дополнительное время на тестирование и отладку, чтобы убедиться, что измененный код отображения по-прежнему работает после удаления кода печати.

- Новый модуль печати, который должен был быть разработан как неотъемлемая часть системы, должен быть разработан на основе существующей системы и вокруг нее, которая не была разработана с учетом этого.
Все это происходит, когда единственной необходимой стоимостью – если правильное решение было принято в нужное время – было спроектировать и внедрить одну версию модуля печати. И теперь вам все равно придется это сделать.
Этот пример не редкость. О выпущенных продуктах, которые были разработаны в условиях чрезмерного графика, сообщается в четыре раза больше обычного количества дефектов2. Внимание к качеству рассматривается как роскошь. В результате проекты часто работают тупее, что приводит к еще более серьезным проблемам с расписанием.
Модули, подверженные ошибкам
Одним из аспектов обеспечения качества, который особенно важен для быстрой разработки, является наличие подверженных ошибкам модулей, то есть модулей, ответственных за непропорционально большое количество дефектов. Барри Бём сообщил, что 20 % модулей в программе обычно вызывают 80 % ошибок5. В своем проекте IMS IBM обнаружила, что 57 % ошибок приходится на 7 % модулей1.
Барри Бём сообщил, что 20 % модулей в программе обычно вызывают 80 % ошибок5. В своем проекте IMS IBM обнаружила, что 57 % ошибок приходится на 7 % модулей1.
Модули с такими высокая доля дефектов требует больших затрат и времени на доставку, чем менее подверженные ошибкам модули. Обычные модули стоят от 500 до 1000 долларов за каждую функциональную точку для разработки. Модули, подверженные ошибкам, стоят от 2000 до 4000 долл. США за единицу функциональной точки для разработки2. Модули, подверженные ошибкам, как правило, более сложны, чем другие модули в системе, менее структурированы и необычно велики. Они часто разрабатывались в условиях чрезмерного графика и не были полностью протестированы.
Если важна скорость разработки, сделайте приоритетом идентификацию и перепроектирование подверженных ошибкам модулей. Как только уровень ошибок в модуле достигает примерно 10 дефектов на тысячу строк кода, проверьте его, чтобы определить, следует ли его перепроектировать или реализовать заново. Если он плохо структурирован, чрезмерно сложен или чрезмерно длинен, перепроектируйте модуль и заново реализуйте его с нуля. Вы сократите сроки и одновременно улучшите качество своего продукта.
Если он плохо структурирован, чрезмерно сложен или чрезмерно длинен, перепроектируйте модуль и заново реализуйте его с нуля. Вы сократите сроки и одновременно улучшите качество своего продукта.
Обеспечение качества и скорость разработки
Если вы можете предотвращать дефекты или обнаруживать и устранять их на ранней стадии, вы можете значительно сократить сроки. Исследования показали, что на исправление дефектных требований, дизайна и кода обычно уходит от 40 до 50 процентов общих затрат на разработку программного обеспечения (Jones, 1986). Как правило, каждый час, который вы тратите на предотвращение дефектов, сокращает время ремонта с трех до десяти часов. переделывать задачу на стадии требований (Бём и Папаччо 19).88). Легко понять, почему. Требование в 1 предложение может расшириться до 5 страниц проектных диаграмм, затем до 500 строк кода, 15 страниц пользовательской документации и нескольких десятков тестовых случаев. Дешевле исправить ошибку в этом требовании из 1 предложения во время разработки требований, чем после того, как к нему будут написаны дизайн, код, пользовательская документация и тестовые примеры.
На рис. 2 показано, как дефекты становятся тем дороже, чем дольше они остаются в программе.
Рис. 2. Чем дольше дефект остается незамеченным, тем дороже становится его исправление.
гифка
Потенциал экономии от раннего обнаружения дефектов огромен — около 60 процентов всех дефектов обычно уже существуют на этапе проектирования (Gilb 1988), и вы должны попытаться устранить их на этапе проектирования. Решение на ранней стадии проекта не сосредотачиваться на обнаружении дефектов равносильно решению отложить обнаружение и исправление дефектов до более поздних этапов проекта, когда они будут намного более дорогими и трудоемкими. Это не рациональное решение, когда время в дефиците.
Методы обеспечения качества
Различные меры обеспечения качества по-разному влияют на скорость разработки. Вот краткое изложение.
Презентации
Наиболее распространенным методом обеспечения качества, несомненно, является тестирование выполнения, поиск ошибок путем выполнения программы и наблюдения за тем, что происходит. Двумя основными видами исполнительного тестирования являются модульные тесты, в которых разработчик проверяет свой собственный код, чтобы убедиться, что он работает правильно, и системные тесты, в которых независимый тестировщик проверяет, работает ли система так, как ожидается.
Двумя основными видами исполнительного тестирования являются модульные тесты, в которых разработчик проверяет свой собственный код, чтобы убедиться, что он работает правильно, и системные тесты, в которых независимый тестировщик проверяет, работает ли система так, как ожидается.
Тестирование — это белая воронка в методах обеспечения качества с точки зрения скорости разработки. Это конечно можно сделать настолько коряво, что замедлит график разработки, но чаще всего его влияние на график только косвенное. Тестирование обнаруживает, что качество продукта слишком низкое для его выпуска, и продукт приходится откладывать до тех пор, пока его можно будет улучшить. Таким образом, тестирование становится вестником плохих новостей.
Лучший способ использовать тестирование с точки зрения быстрой разработки — заранее спланировать плохие новости — настроить тестирование таким образом, чтобы, если есть плохие новости, тестирование доставляло их как можно раньше.
Технические обзоры
Технические обзоры включают в себя все виды обзоров, которые используются для обнаружения дефектов в требованиях, дизайне, коде, тестовых примерах и других рабочих продуктах. Обзоры различаются по уровню формальности и эффективности, и они играют более важную роль в максимизации скорости разработки, чем тестирование.
Обзоры различаются по уровню формальности и эффективности, и они играют более важную роль в максимизации скорости разработки, чем тестирование.
Наименее формальным и наиболее распространенным видом обзора является пошаговое руководство, то есть любое собрание, на котором два или более разработчиков анализируют техническую работу с целью улучшения ее качества. Пошаговые руководства полезны для быстрой разработки, поскольку их можно использовать для обнаружения дефектов раньше, чем при тестировании.
Чтение кода — это несколько более формальный процесс просмотра, чем пошаговое руководство, но номинально применяется только к коду. При чтении кода автор кода раздает исходные коды двум или более рецензентам. Рецензенты читают код и сообщают обо всех ошибках автору кода. Исследование, проведенное в Лаборатории разработки программного обеспечения НАСА, показало, что чтение кода выявляет в два раза больше дефектов за час усилий, чем тестирование (Card 1987). Это говорит о том, что в проекте быстрой разработки некоторая комбинация чтения кода и тестирования будет более эффективной по графику, чем только тестирование.
Инспекции являются наиболее формальным видом технической проверки, и было установлено, что они чрезвычайно эффективны при обнаружении дефектов на протяжении всего проекта. Разработчики обучены использованию методов проверки и играют определенные роли в процессе проверки. Перед инспекционным совещанием «модератор» раздает материалы для проверки. «Рецензенты» изучают материал перед встречей и используют контрольные списки, чтобы стимулировать свои обзоры. Во время инспекционного совещания «автор» перефразирует материал, рецензенты выявляют ошибки, а «писец» фиксирует ошибки. После встречи модератор составляет отчет о проверке, в котором описывается каждый дефект и указывается, что с ним будет сделано. В процессе проверки вы собираете данные о дефектах, часах, потраченных на исправление дефектов, и часах, потраченных на проверки, чтобы вы могли проанализировать эффективность вашего процесса разработки программного обеспечения и улучшить его.
Поскольку их можно использовать на ранних этапах цикла разработки, было обнаружено, что инспекции обеспечивают чистую экономию времени от 10 до 30 процентов (Gilb and Graham 1993). Одно исследование крупных программ даже показало, что каждый час, затраченный на проверки, позволяет избежать в среднем 33 часов технического обслуживания, а проверки в 20 раз эффективнее испытаний (Russell, 1991).
Одно исследование крупных программ даже показало, что каждый час, затраченный на проверки, позволяет избежать в среднем 33 часов технического обслуживания, а проверки в 20 раз эффективнее испытаний (Russell, 1991).
Комментарий к техническим обзорам
Технические обзоры являются полезным и важным дополнением к тестированию. Обзоры обнаруживают дефекты раньше, что экономит время и хорошо для графика. Они более эффективны с точки зрения затрат в расчете на каждый обнаруженный дефект, поскольку они одновременно обнаруживают как симптом дефекта, так и основную причину дефекта. Тестирование выявляет только симптом дефекта; разработчик по-прежнему должен изолировать причину путем отладки. Обзоры, как правило, обнаруживают более высокий процент дефектов (Джонс 1986). А обзоры служат временем, когда разработчики делятся друг с другом своими знаниями о передовом опыте, что со временем увеличивает их способность к быстрой разработке. Таким образом, технические обзоры являются важнейшим компонентом любых усилий по разработке, направленных на достижение кратчайшего графика.
Другой вид качества
В начале статьи я упомянул, что существует два вида качества. Другой вид качества включает в себя все другие характеристики, о которых вы думаете, когда думаете о высококачественном программном продукте: удобство использования, эффективность, надежность, ремонтопригодность, переносимость и так далее. В отличие от качества с низким уровнем брака, внимание к этому виду качества имеет тенденцию удлинять график разработки.
Резюме
Когда в программном продукте слишком много дефектов, разработчики тратят больше времени на исправление программного обеспечения, чем на его написание. Большинство организаций обнаружили, что важным ключом к достижению максимально коротких графиков является сосредоточение их процессов разработки на том, чтобы они выполняли свою работу правильно с первого раза. «Если у тебя нет времени сделать работу как следует, — говорит старый каштан, — где ты найдешь время, чтобы переделать ее заново?»
Дополнительные показания
Публикации, включенные в этот список, также упоминаются в этой статье. Используйте их в своих интересах при поиске дополнительных деталей по этому вопросу.
Используйте их в своих интересах при поиске дополнительных деталей по этому вопросу.
Бём, Барри В. «Повышение производительности программного обеспечения». IEEE Computer, , сентябрь 1987 г., стр. 43–57.
Бём, Барри В. и Филип Н. Папаччо. «Понимание и контроль затрат на программное обеспечение», IEEE Transactions on Software Engineering, v. 14, no. 10 октября 1988 г., стр. 1462-1477.
Card, Дэвид Н. «Программа оценки программных технологий», Информационные и программные технологии , т. 29, вып. 6, июль/август 1987 г., стр. 291-300.
Гилб, Том и Дороти Грэм. Software Inspection (Wokingham, England: Addison-Wesley), 1993.
Gilb, Tom. Principles of Software Engineering Management (Вокингем, Англия: Addison-Wesley), 1988.
Jones, Capers, изд. Учебное пособие: Продуктивность программирования: Проблемы восьмидесятых, 2-е изд. (Лос-Анджелес: IEEE Computer Society Press), 1986.
Джонс, Каперс.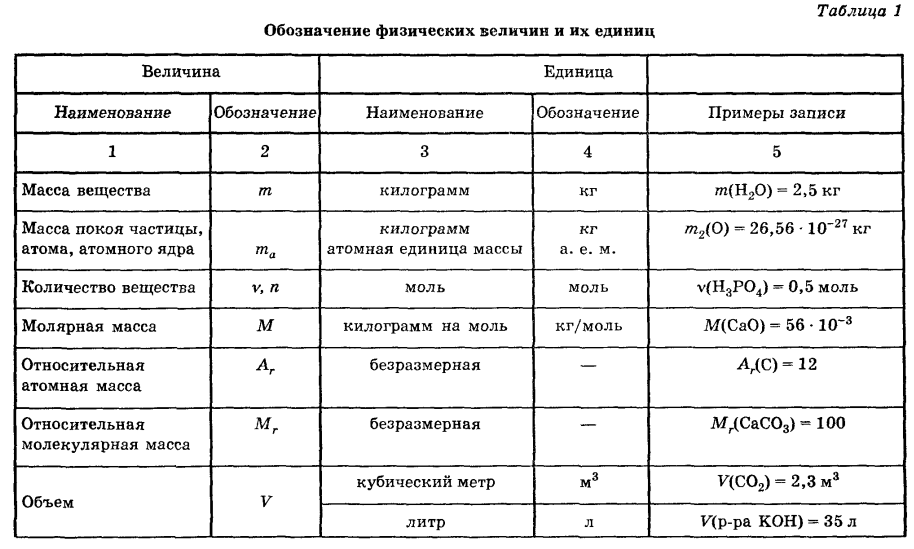 Измерение прикладного программного обеспечения: обеспечение производительности и качества . Нью-Йорк: McGraw-Hill, 1991.
Измерение прикладного программного обеспечения: обеспечение производительности и качества . Нью-Йорк: McGraw-Hill, 1991.
Джонс, Каперс. Оценка и контроль программных рисков . Englewood Cliffs, NJ: Yourdon Press, 1994.
Jones, Capers. Programming Productivity (Нью-Йорк: McGraw-Hill), 1986.
Китсон, Дэвид Х. и Стивен Мастерс. «Анализ результатов оценки программного процесса SEI, 1987-1991». В Proceedings of the Fifteenth International Conference on Software Engineering (Washington, DC: IEEE Computer Society Press), 1993, стр. 68–77. Программное обеспечение IEEE , том. 8, нет. 1 (январь 1991 г.), стр. 25-31.
Автор: Стив МакКоннелл, Construx Software | Еще статьи
Ссылка для загрузки страницы Перейти к началупоказателей производительности процесса
Мы можем использовать множество показателей производительности процессов для измерения текущей и будущей ценности наших процессов.
Прежде чем мы рассмотрим метрики, давайте рассмотрим некоторые термины, которые мы будем использовать. Важно, чтобы вы понимали эти термины так, как они используются в программе «Шесть сигм».
Терминология
- Дефект: Конечный результат (часто продукт), который не попадает в заранее определенный допустимый диапазон значений. Эти значения могут быть показателями прочности и/или размера физического продукта. Для службы эти значения могут быть ключевыми показателями эффективности, такими как время обработки. В общем смысле дефектом считается несоответствие ожиданий потребителя в отношении качества.
- Возможность: Шанс повысить ценность для клиента. Это относится к любой ситуации, в которой ваша компания может повысить воспринимаемую ценность продукта или услуги. Например, если вы производите продукт по спецификациям клиентов, ваши возможности могут быть следующими:
- Соответствие физическим требованиям заказчика
- Сроки соблюдения
- Предоставление бесплатной курьерской услуги прямо к заказчику.
- Единица: Ощутимый результат для клиента: отдельная услуга или продукт. Например, телефонный звонок клиента в ваш отдел обслуживания — это единица.
- Доходность: Доходность — это процент от возможностей , которые были успешно реализованы. Еще один способ посмотреть на выход — это процент бездефектных процессов.
Доходность = (Возможности - Дефекты) / Возможности
Возможности и подразделения
Легко перепутать возможности и подразделения. Самый простой способ их дифференцировать — это учитывать потребности и требования клиентов.
Им нужен блок .
Спецификации этого предмета (цвет, размер, материалы, время доставки) возможности .
У вас может быть несколько возможностей на единицу. Например,
подумайте о клиенте, звонящем в службу поддержки, чтобы получить помощь с частью
программное обеспечение. Единицей в данном случае является телефонный звонок.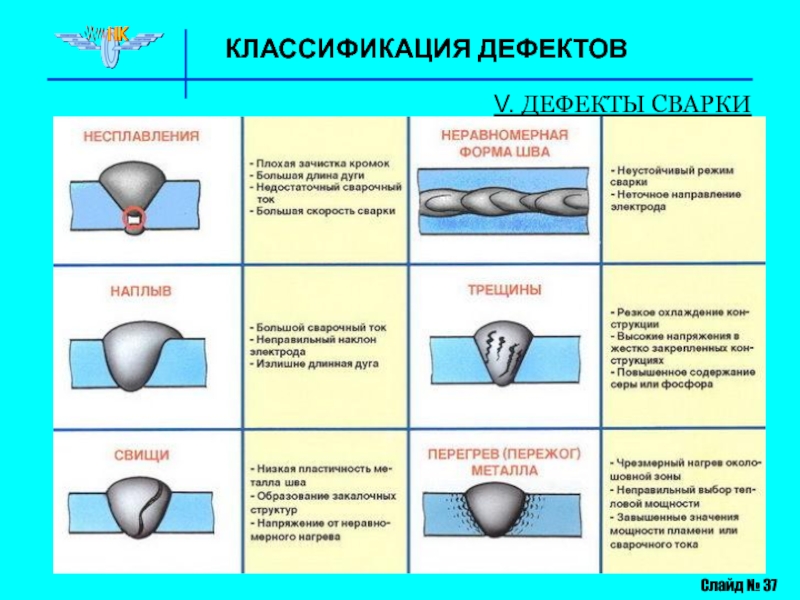 Возможности могут быть следующими:
Возможности могут быть следующими:
- Ответ на телефонный звонок в пределах допустимого диапазона времени.
- Телефонный звонок направлен соответствующему лицу.
- Возможность помочь клиенту с его проблемой.
- У клиента остались положительные впечатления.
Показатели производительности процесса — количество дефектов на возможность (DPO)
DPO означает количество дефектов на возможность. Это простое соотношение. Возьмите количество дефектов, которые вы имеете в своем процессе (обычно обнаруживаемых путем выборки), и разделите его на количество имеющихся возможностей. Затем выразите соотношение в процентах.
DPO = Дефекты/Возможности
Сложные процессы и элементы часто имеют много возможностей для добавления ценности. Следовательно, у вас может быть несколько дефектов для каждого процесса или элемента.
Пример: заказ еды из фаст-фуда. У клиента есть множество критериев, по которым он будет судить об опыте в целом:
- Отношение персонала
- Скорость обслуживания
- Точность (соответствуют ли полученные предметы заказать?)
- Презентация
- Вкус еды
- Свежесть/жаркость пищи.
Каждый из этих критериев — это возможность повысить ценность для клиента. Несоблюдение любого из этих критериев снижает ценность и считается дефектом. Если покупателю приходится ждать десять минут (дефект в скорости обслуживания), он получает не тот бургер (дефект в точности), а его бургер тепловатый (дефект свежести/теплоты), каждый из трех дефектов уменьшает стоимость конечного результата. .
Потенциальная ошибка: Убедитесь, что вы используете дефекты и возможности для одной и той же группы населения. Например, если вы подсчитываете дефекты в выборке из 500 продуктов, количество возможностей также должно относиться только к этой выборке из 500 продуктов.
Примеры дефектов на каждую возможность
Предположим, закусочная Joe’s Burgers обслуживает 1000 клиентов в день. Компания определила свои типы возможностей следующим образом:
- Точность
- Скорость
- Свежесть
- Вкус
Например, за один день 50 клиентов получили неправильный заказ, 75 посчитали, что ждали слишком долго, 25 сказали, что их заказ был холодным, и еще 50 сказали, что их гамбургеры просто невкусные.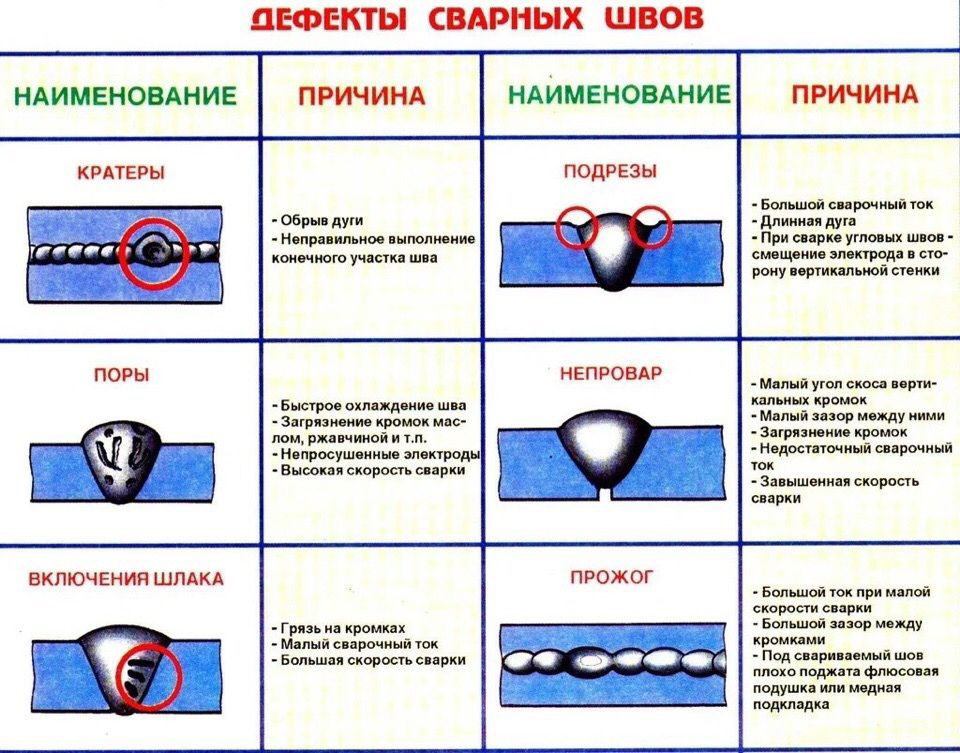
Некоторые из этих отзывов могли перекрываться; клиенты могли получить неправильный заказ и слишком долго его ждали. Это не имеет значения для этой метрики, потому что к каждому заказу привязано несколько возможностей.
Чтобы рассчитать количество возможностей, умножьте количество заказов (1000) на количество типов возможностей (4), чтобы получить 4000.
DPO = количество дефектов / количество возможностей = 200/4000 = 0,05 = 5%
Показатели производительности процесса – дефектов на единицу (DPU) )
Дефекты на единицу — расчет, аналогичный DPO, но вместо рассмотрения возможностей мы рассматриваем единицы. См. «Возможность против единицы» выше, если вы запутались.
Давайте снова посмотрим на пример с закусочной Джо, но на этот раз с точки зрения ДПУ.
Примеры дефектов на единицу
Предположим, закусочная Joe’s Burgers обслуживает 1000 клиентов в день. В
за один день 50 клиентов ошиблись в заказе, 75 посчитали, что ждали слишком долго, 25
сказали, что их заказ был холодным, и еще 50 человек сказали, что их гамбургеры просто невкусные.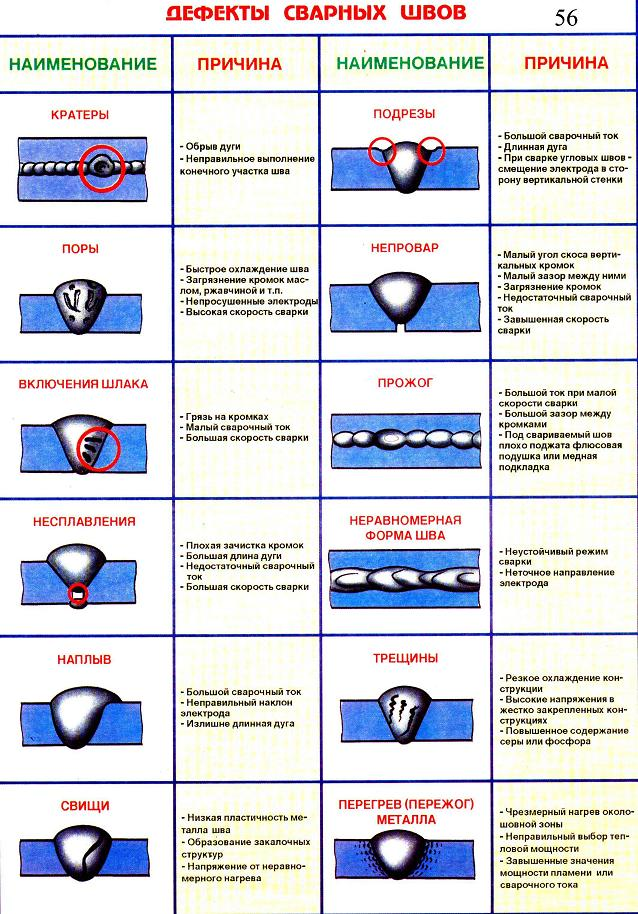
Некоторые из этих отзывов могли перекрываться; клиенты могут получили не тот заказ и слишком долго его ждали. Это не имеет значения для этой метрики. Мы просто ищем базовое соотношение.
(Примечание: это имело бы значение , если бы мы говорили о дефектных единиц на 1000, например.)
Количество единиц соответствует количеству заказов (1000).
DPU = количество дефектов / количество единиц ДПУ = 200/1000 = 0,2 DPU = 20 %
Показатели производительности процесса — количество дефектов на миллион возможностей (DPMO)
DPMO основан на DPO, но использует реальные производственные показатели. Это важная метрика, потому что она используется в Six Sigma для измерения производительности процесса. Например, Joe’s Burgers будет использовать DPMO, чтобы определить, насколько успешен их текущий процесс обслуживания и как он сравнивается с другими процессами обслуживания, которые они, возможно, пробовали.
Дефектов на миллион Возможности обычно экстраполируются из выборки.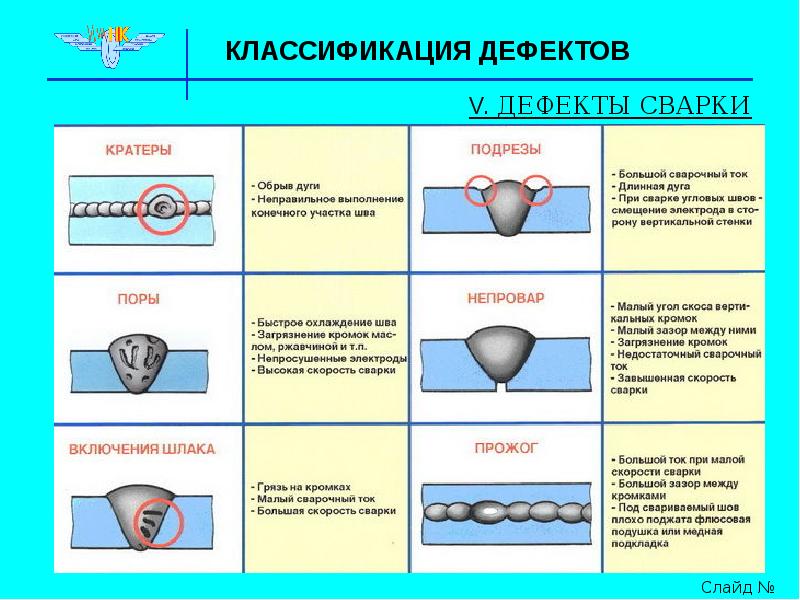 В приведенных выше примерах работы мы рассмотрели Joe’s Burgers, взяв за образец заказы за один день — 1000 единиц. Если вы уже рассчитали DPO для образца, вы можете рассчитать DPMO, просто умножив десятичный результат (не процент) на один миллион.
В приведенных выше примерах работы мы рассмотрели Joe’s Burgers, взяв за образец заказы за один день — 1000 единиц. Если вы уже рассчитали DPO для образца, вы можете рассчитать DPMO, просто умножив десятичный результат (не процент) на один миллион.
DPMO = DPO * 1000000
В качестве альтернативы можно использовать это уравнение:
DPMO = (Дефекты/Возможности) * 1000000
Или:
DPMO = (Дефекты / (размер выборки * возможности на единицу)) * 1000000
Рабочий пример дефектов на миллион возможностей
Joe’s Burgers обслуживает 1000 клиентов в день. Компания определила свои типы возможностей следующим образом:
- Точность
- Скорость
- Свежесть
- Вкус.
За один день 50 клиентов ошиблись в заказе, 75 посчитали они ждали слишком долго, 25 сказали, что их заказ был холодным, и еще 50 сказали, что их гамбургеры просто невкусные.
Количество дефектов: 50 + 75 + 25 + 50 = 200 Размер выборки: 1000 Возможностей на единицу: 4 DPMO = (Дефекты / (размер выборки * возможности на единицу)) * 1000000 DPMO = (200/(1000 * 4)) * 1000000 DPMO = 50000
Как рассчитать уровень 6 сигм на основе DPMO
Существует два основных способа определения уровня 6 сигм по цифре DPMO:
- Посмотрите на таблицу в приложении.

- Используйте уравнение.
Уравнение уровня шести сигм
Используйте это уравнение для расчета уровня шести сигм вашего процесса на основе его DPMO:
Уровень = 0,8406 + √(29,37 – (2,221 * ln(DPMO)))
Примечание. Если вам интересно, где числа 0,8406, 29,37 и 2,221, они являются константами, которые помогают нам просто рассчитать DMPO или уровень.
Сигма процесса = 0,8406 + SQRT(29,37 – 2,221 * (ln(DPMO))).
Ссылка: Breyfogle, F., 1999. Внедрение шести сигм: более разумные решения с использованием статистических методов . 2-е изд. Джон Уайли и сыновья.
Рабочий пример вычисления уровня Шесть сигм
Начнем с цифры DPMO от Joe’s Burgers: 50000.
Во-первых, если вы не встречали в раньше, значит, вам нужно найти натуральный логарифм номер — в данном случае DPMO. Используйте научный калькулятор. В этом случае натуральный логарифм 50000 с точностью до 4 знаков после запятой равен 10,8198.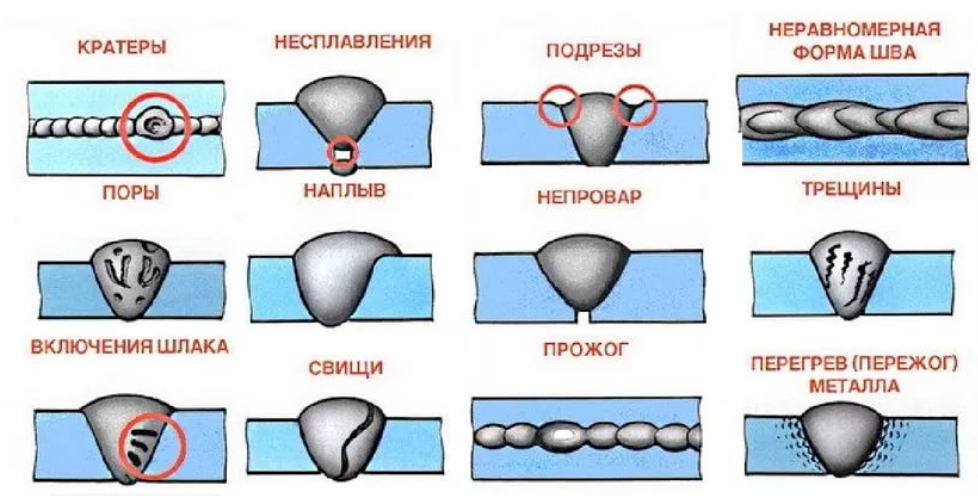
Во-вторых, нам нужно подставить это в уравнение:
Уровень = 0,8406 + √(29,37 – (2,221 * ln(50000)) Уровень = 0,8406 + √(29,37 – (2,221 * 10,8198)) Уровень = 0,8406 + √(29,37 - 24,0307) Уровень = 0,8406 + √(29,37 - 24,0307) Уровень = 0,8406 + √5,3392 Уровень = 0,8406 + 2,3106 Уровень = 3,1513
DPMO_Sigma_Value_TemplateDownload
Первичный выход (FTY)
Первый выход — наиболее распространенный способ расчета технологического выхода. Это количество бездефектных единиц, выходящих из процесса, по сравнению с количеством произведенных единиц. Другими словами, это вероятность бездефектного выхода процесса.
FTY не фиксирует, сколько дефектов перерабатывается на каждом этапе. Другими словами, в него не входят единицы, которые должны быть переработаны в бездефектные единицы. Он не обнаружит влияние скрытых факторов.
FTY — это количество произведенных качественных деталей, деленное на общее количество деталей, поступающих в процесс.
Как рассчитать FTY для процесса
- Рассчитать первоначальный выход для каждого этапа процесса на основе количества бездефектных единиц, поступающих на каждый этап (как правило, на каждом этапе будет меньше единиц, чем на предыдущем этапе ).

- Перемножьте значения FTY, чтобы получить общий выход продукции при первом проходе.
FTY t = FTY 1 * FTY 2 * FTY 3 * ... * FTY n
Где:
т всего Первый раз Выход для процесса.
n — количество шагов в процессе.Рабочий пример расчета FTY
Пример: На заводе-изготовителе 100 деталей поступают в первый процесс, 2 утилизируются, а 98 бездефектных деталей переходят на следующий этап. Из 98 деталей, поступающих на второй процесс, 5 бракуются, а 93 бездефектные детали переходят на следующий этап. Из 93 деталей, поступающих на третий процесс, 10 утилизируются, а 83 бездефектные детали переходят на следующий этап. Найдите выход с первого раза.
Найдите выход с первого раза.
- Первый процесс: 100 деталей входят в процесс; 2 списаны, т.е. выход 98 деталей; FTY1 = (100 – 2)/100 = 98/100= 0,98
- Второй процесс: 98 деталей входят в процесс; 5 списано, т.е. вышло 93 детали; FTY2 = (98 – 5)/98 = 93/98 = 0,9489
- Третий процесс: в процесс входят 93 детали; 10 списано, т.е. вышло 83 детали; FTY3 = (93 – 10)/93 = 83/93 = 0,8924
Общий выход продукции с первого раза = 0,98*0,9489*0,8924= 0,829 ~ выход 83% %
Rolled Throughput Yield (RTY)
Rolled Throughput Yield (RTY) — отличный способ увидеть состояние процесса. RTY обеспечивает вероятность того, что процесс без дефектов сгенерирует единицу. Другими словами, это вероятность того, что в результате многоэтапного процесса будет получена единица без дефектов.
Пропускная способность проката более мощная, поскольку она чувствительна к дефектам. Вместо того, чтобы основываться на доходе в единицах, он использует количество дефектов на каждом этапе (даже если дефектная деталь будет исправлена, она все равно будет учитываться при расчете RTY). Это ценно для организаций, так как большинство из них рассматривает только успешные/пройденные единицы, хотя присущая муда присутствует. RTY учитывает общее количество дефектов во всем процессе.
Это ценно для организаций, так как большинство из них рассматривает только успешные/пройденные единицы, хотя присущая муда присутствует. RTY учитывает общее количество дефектов во всем процессе.
Перед расчетом RTY необходимо выполнить два важных шага:
- Составьте схему процесса, чтобы знать, сколько в нем шагов.
- Отбирайте образцы на каждом этапе процесса и проверяйте их на наличие дефектов, чтобы у вас были данные для расчета.
Пример
Последовательность из 3 операций имеет следующие коэффициенты выхода продукции при первом проходе (правильный первый раз):
- 1-й шаг: 93%
- 2-й шаг: 87%
- 3-й шаг: 92%.
Другими словами, вероятность правильного завершения первого шага процесса составляет 93%. Шанс 2-го только 87%. И третий шаг процесса имеет шанс 92%.
Производительность первого прохода для всего процесса представляет собой умножение вероятности каждого шага.
RTY = 93% * 87% * 92% = 74%
Каждый шаг сам по себе имел хорошие шансы быть принятым. Но когда вы посмотрите на всю систему, вы увидите, что совокупные ошибки сказываются. В приведенном выше примере любой элемент, созданный в процессе, имел только 74% шанс пройти без ошибок или переделок.
Но когда вы посмотрите на всю систему, вы увидите, что совокупные ошибки сказываются. В приведенном выше примере любой элемент, созданный в процессе, имел только 74% шанс пройти без ошибок или переделок.
Рабочий пример расчета пропускной способности проката
Пример: На производственном предприятии 100 деталей поступают в первый процесс, 2 утилизируются, а 5 перерабатываются, чтобы передать 98 деталей на следующий этап. 98 деталей поступают во второй процесс, где 5 утилизируются, а 10 перерабатываются для получения 93 деталей. 93 детали поступают в третий процесс, где 10 утилизируются, а 5 перерабатываются, чтобы получить 83 детали. Найдите пропускную способность проката.
- Первый процесс: 100 деталей входят в процесс; 2 списаны и 5 переработаны, так что выход 98 частей; RTY1 = (100 – (2+5))/100 = 93/100 = 0,93
- Второй процесс: 98 деталей входят в процесс; 5 списано и 10 переработано, так что вышло 93 детали; RTY2 = (98 – (5+10))/98 = 83/98 = 0,85
- Третий процесс: в процесс входят 93 детали; 10 списано и 5 переработано, так что вышло 83 детали; RTY3 = (93 – (10+5))/93 =78/93= 0,84
Таким образом, общая пропускная способность = 0,93*0,85*0,84= 0,664 ~ выход 66% Дефектов на единицу. Используйте это уравнение:
Используйте это уравнение:
DPU = -ln(RTY)
Напоминание: ln — натуральный логарифм.
Рабочий пример расчета DPU по RTY
Из приведенного выше производственного примера RTY составляет примерно 69,5%. Затем, чтобы получить DPU, мы подставляем его в уравнение:
DPU = -ln(0,695) DPU = 0,3638
Rolled-Throughput-Yield-TemplateDownload
Использование метрик производительности процесса
После того, как вы поймете, какие метрики производительности доступны и как их использовать, следующим шагом будет решить, какие метрики использовать.
Первичные и вторичные метрики производительности процесса
Первичные и вторичные метрики не являются статичными. Каждая организация будет иметь свои приоритеты в отношении показателей эффективности процессов, что приводит к разным спискам первичных и вторичных показателей. Эти списки будут время от времени меняться по мере изменения фокуса организации и бизнес-целей.
Вообще говоря, основные показатели производительности процессов — это те, на которых ваша организация решает сосредоточиться больше всего. Остальное — второстепенные показатели производительности процесса.
Остальное — второстепенные показатели производительности процесса.
Вопросы, которые следует задать при разработке программы показателей эффективности процессов
Следующая информация была отправлена мне по электронной почте и приписана Уиллу Поутсу из CEB.
Группы бухгалтерского учета и отчетности всегда стараются включать в свои управленческие отчеты наиболее важные метрики, поэтому при включении метрик им следует избегать трех следующих ошибок: неправильный выбор метрики, отсутствие ответственности за процесс и неэффективные методы отчетности.
Ниже приведены 13 вопросов, которые вы можете задать себе и членам своей команды при разработке или усилении вашей программы показателей.
- Выбрали ли мы не более 12–15 показателей для принятия решений из числа предложенных руководством отдела корпоративных финансов и деловыми партнерами?
- Согласны ли мы с определением каждой метрики, причиной ее отслеживания и целью, к которой мы стремимся?
- Можем ли мы связать каждую метрику с бизнес-целью или корпоративной целью?
- Протестировали ли мы метрики с нашими заинтересованными сторонами, чтобы убедиться, что они понимают определение и имеют четкое представление о том, как они будут использовать метрику для принятия решений?
- Проверить, включили ли мы качественные и количественные показатели в нашу структуру принятия решений?
- Знаем ли мы, какие параметры детализации наиболее полезны для каждой метрики?
- Кроме того, знаем ли мы, какие стили представления метрик предпочитает каждая заинтересованная сторона?
- Запускали ли мы каждую метрику в течение пробного периода, чтобы установить базовый уровень?
- Проверить, согласовали ли мы триггеры или циклы обновления для каждой метрики, чтобы предотвратить их устаревание?
- Есть ли у нас метрика, которая может предсказать будущие проблемы?
- Чувствуют ли себя деловые партнеры удобными для оповещения финансового отдела, когда показатели необходимо изменить и адаптировать к новым условиям?
- Исключаем ли мы старые показатели, когда новые становятся более репрезентативными?
- Наконец, сообщаем ли мы нашим деловым партнерам о метриках, которые мы больше не будем отслеживать при изменении панели мониторинга?
Вопросы эффективности процесса сертификации «черный пояс шести сигм»:
Вопрос: Какой из следующих показателей эффективности наиболее подходит для оценки ощутимых результатов проекта «Шесть сигм»? (Взято из экзамена на получение черного пояса ASQ. )
)
a) Время цикла
b) Коэффициент отсутствия членов команды
C) Моральный дух сотрудников
D) Непрошенные комплименты от клиентов
Ответ:
4 9 Разблокировать дополнительных участников -только Контент! Чтобы разблокировать дополнительный контент, перейдите на полноценную подписку.
Обновление до полного членства
Если вы зарегистрированы, вы можете войти здесь.
Вопрос: Какая из следующих формул является правильной для DPMO?
(A) D/TOP
(B) DPO X 1,000,000
(C) D X U XOP
(D) DPU/DPO
Ответ:
Разблокируйте дополнительный контент только для членов!
Чтобы разблокировать дополнительный контент, перейдите на полноценную подписку.Обновление до полного членства
Если вы зарегистрированы, вы можете войти здесь.
ASQ «Зеленый пояс шести сигм» Вопросы эффективности процесса
Вопрос: Какой из следующих показателей используется для отображения отношения дефектов к единицам?
(A) DPU
(B) DPO
(C) DPMO
(D) PPM
Ответ:
Разблокируйте дополнительный контент только для членов!
Чтобы разблокировать дополнительный контент, перейдите на полноценную подписку.